Table des matières
Articles reliés
Gestion des problèmes - Module Octopus
Introduction
La gestion des problèmes est un processus ITIL® qui fait partie de la phase Exploitation des services :
But & Objectifs
La gestion des problèmes est un processus ITIL® responsable de la gestion du cycle de vie de tous les problèmes. Les objectifs principaux sont de prévenir proactivement que des incidents ne surviennent et minimiser l'impact de ceux qui ne peuvent être évités.
Portée
La gestion des problèmes inclut les activités requises pour diagnostiquer la cause fondamentale des incidents et détermine la résolution de ces problèmes. Elle est aussi responsable de s'assurer que la résolution est implantée selon des procédures de contrôle appropriées, comme la gestion des changements et la gestion des déploiements & mises en production.
De plus, la gestion des problèmes maintient l'information concernant les problèmes, les solutions de contournement et les résolutions, de manière à viser la réduction du nombre et l'impact des incidents au fil du temps.
Même si la gestion des incidents et la gestion des problèmes sont des processus séparés, ils sont étroitement liés et vont utiliser les mêmes outils, une catégorisation similaire, ainsi que le même système de priorité.
Valeur
La gestion des problèmes travaille avec la gestion des incidents et la gestion des changements afin de d'assurer que la disponibilité et la qualité des services TI s'améliorent. Lorsque les incidents sont résolus, l'information de résolution est enregistrée. Au fil du temps, cette information est utilisée pour accélérer le temps de résolution et d'identifier des solutions permanentes, réduisant ainsi le nombre et le temps de résolution des incidents. Cela se traduit par moins de pannes et moins de perturbations pour les systèmes critiques de l'entreprise.
On constate aussi :
- Meilleure disponibilité des services TI.
- Meilleure productivité de la business et du personnel TI.
- Réduction des dépenses sur des solutions de contournement ou des correctifs qui ne fonctionnent pas.
- Réduction du coût de l'effort pour éteindre des feux ou dans la résolution des incidents à répétition.
Définitions
Veuillez consulter la section Gestion des problèmes du glossaire ITIL®.
Activités
La gestion des problèmes consiste en deux sous-processus :
- Gestion des problèmes réactifs : habituellement exécutée à l'intérieur des opérations.
- Gestion des problèmes proactifs : initiée dans l'Exploitation des services, elle est généralement conduite par l'Amélioration continue des services.
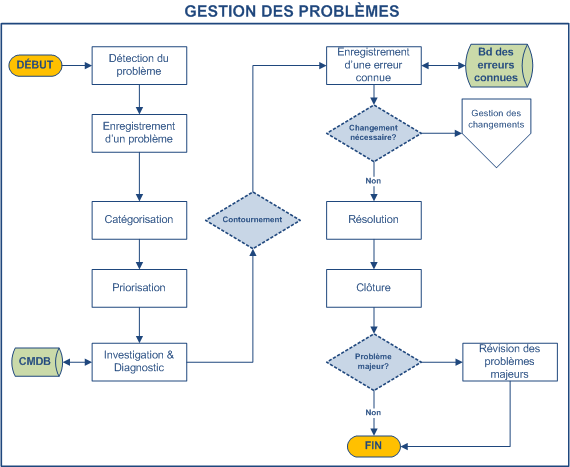
Détection : Selon l'organisation, la détection des problèmes peut différer. Elle inclut :
- Suspicion ou détection d'une cause inconnue d'un ou de plusieurs incidents par le Centre de services. L'incident peut avoir été résolu, mais une cause définitive n'a pas été déterminée et l'incident est susceptible de se reproduire. Ou encore, il peut être évident dès le départ qu'un ou plusieurs incidents aient été causés par un problème majeur. Dans ce cas, une requête de type problème sera créée sans délai.
- Analyse d'un incident par un groupe de soutien technique qui révèle qu'un problème sous-jacent existe, ou est susceptible d'exister.
- Détection automatique d'un défaut de l'infrastructure ou d'une application, en utilisant automatiquement un outil d'alertes (événements) capable de créer un incident qui pourrait nécessiter la création d'un problème.
-
Une notification d'un fournisseur qu'il existe un problème qui doit être résolu.
-
Analyse des incidents survenus afin de rechercher une cause fondamentale et une solution de contournement ou permanente.
Une analyse régulière des incidents et problèmes doit être effectuée afin d'identifier les tendances à mesure qu'elles deviennent perceptibles, afin d'identifier les zones de forte occurrence.
Enregistrement : Quelle que soit la méthode de détection, les détails pertinents d'un problème doivent être enregistrés. Une relation entre le ou les incidents et un problème doit être possible. Certaines informations de l'incident doivent être transférées dans le problème, telles que :
- Détails de l'utilisateur
- Détails du service
- Détails de l'équipement
- Date/heure d'enregistrement
- Priorité et catégorisation
- Description
- Détails du diagnostic ou actions de résolution
Catégorisation : Les problèmes doivent être catégorisés de la même manière que les incidents de sorte qu'un problème et l'information pertinente soient facilement retrouvés.
Priorité : Les problèmes doivent être priorisés de la même façon et pour les mêmes raisons que les incidents. Cependant, la fréquence et l'impact des incidents reliés doivent être pris en considération. La matrice de priorité, dont la dérivation est faite selon l'impact et l'urgence, peut être utilisée, à condition que les définitions et les directives sur ce que constitue un problème soient élaborées et communiquées aux groupes impliqués dans la gestion des problèmes.
La priorité d'un problème doit aussi tenir compte du niveau de criticité d'un problème, qui réfère dans le présent contexte au sérieux du problème dans une perspective d'infrastructure. Exemples :
- Est-ce que le système peut être récupéré ou nécessite-t-il un remplacement?
- Combien cela va-t-il coûter?
- Combien de personnes et quelles expertises techniques sont nécessaires pour résoudre le problème?
- Combien de temps cela prendra-t-il pour résoudre le problème?
- Quelle est l'étendue du problème (ex.: combien de CI sont affectés?)?
Investigation & Diagnostic : Une investigation doit être effectuée pour tenter de trouver la cause réelle du problème. La vitesse et la nature de cette investigation varieront selon l'impact, la criticité et l'urgence du problème, mais le niveau approprié de ressources et d'expertise devrait être appliqué pour trouver une solution en rapport avec le code de priorité attribué et la cible de service en place pour ce niveau de priorité.
Le système de gestion des configurations (CMS) est utilisé pour déterminer le niveau d'impact et aide à identifier le point exact d'origine du problème. On peut aussi investiguer si le problème est survenu avant et dans quel contexte afin de trouver une solution.
Il est souvent utile d'essayer de recréer la panne, de manière à mieux comprendre ce qui s'est passé, d'essayer différentes façons de trouver la résolution de problème et ainsi déployer la plus appropriée et la moins dispendieuse. Pour y arriver efficacement sans causer de dérangements auprès des utilisateurs, un environnement test qui reproduit l'environnement de production sera nécessaire.
Il existe plusieurs techniques d'analyse, de diagnostic et de résolution de problèmes. Les plus utilisées sont :
- Analyse chronologique : toutes les données disponibles concernant le problème sont collectées et triées par date et période afin de fournir un bandeau chronologique détaillé.
- Analyse de la valeur de dérangement : aide à identifier l'impact sur la business d'un ou de plusieurs problèmes. Une formule sert à calculer la valeur de dérangement; elle est basée sur le nombre d'utilisateurs affectés, la durée d'indisponibilité, l'impact sur chaque utilisateur et le coût pour la business (si connu).
- Analyse de Kepner & Tregoe : le problème est analysé en termes de quoi, où, quand et étendue. Les causes possibles sont identifiées. La cause la plus probable est testée. La cause réelle est vérifiée.
- Remue-méninges (brainstorming) : technique favorisant la génération d'idées au sein d'une équipe quant à la cause et aux actions potentielles pour résoudre le problème.
- Diagramme d'Ishikawa : technique qui aide une équipe à identifier toutes les causes possibles d’un problème. Conçue à l’origine par Kaoru Ishikawa, le résultat de cette technique est un schéma ressemblant à une arête de poisson.
- Principe de Pareto : technique permettant de définir la priorité des activités. Le principe de Pareto dit que 80 % de la valeur d’une activité est créé par 20 % de l’effort. L’analyse de Pareto est utilisée dans la gestion des problèmes afin de définir la priorité d'investigation des causes possibles d’un problème.
Solution de contournement : il revient à la gestion des problèmes de trouver une solution de contournement aux incidents dont la cause est inconnue, afin de rétablir le service le plus rapidement possible. La gestion des problèmes peut nécessiter du temps pour trouver une cause et identifier une solution permanente, laquelle pourrait impliquer la gestion des changements et la gestion des déploiements & mises en production pour son application. La solution de contournement permettra au Centre de services de résoudre les incidents récurrents ou potentiellement récurrents jusqu'à ce qu'une solution finale soit implantée.
Enregistrement d'une erreur connue : une fois le diagnostic complété et une solution temporaire ou permanente identifiée, le problème devient une erreur connue. Ainsi, si d'autres incidents ou problèmes surviennent, ils peuvent être identifiés et le service restauré plus rapidement.
Résolution : pour résoudre un problème, une solution permanente doit être appliquée afin d'éliminer la source qui cause les incidents. Les solutions touchent souvent l'environnement de production, que ce soit un élément de l'infrastructure ou une application. Dans ce cas, afin d'éviter d'autres difficultés, la solution sera présentée à la gestion des changements, approuvée et planifiée avant d'être appliquée en production. Dans le cas d'un problème urgent qui affecte sérieusement la business, le processus de changement urgent sera invoqué.
Il arrive qu'une solution à un changement soit retardée ou ne soit jamais implantée pour des raisons de budget, parce que l'impact est limité par rapport aux coûts élevés ou simplement parce qu'il n'a pas été priorisé. Dans ce cas, le problème demeure ouvert et on applique la solution de contournement.
Fermeture : lorsqu'un changement a été complété avec succès et que la résolution a été appliquée, le problème devrait être formellement fermé, ainsi que les incidents reliés encore ouverts. La documentation du problème doit être mise à jour afin que le problème résolu contienne toute l'information pertinente pour références futures.
Révision des problèmes majeurs : après l'occurrence d'un problème majeur, une révision est effectuée afin d'identifier les leçons apprises pour références futures. Le groupe devrait examiner :
- Les choses effectuées correctement.
- Les choses qui ont été mal effectuées.
- Qu'est-ce qui devrait être fait dans le futur.
- Comment prévenir la récidive.
- S'il y a eu une quelconque responsabilité de tiers et si des mesures de suivi sont nécessaires.
Ces révisions peuvent être utilisées dans des activités de formation et de sensibilisation du personnel de soutien. Elles offrent des possibilités de documentation de procédures, d'instructions de travail, ou autre, qui serviront au bénéfice d'une meilleure gestion des problèmes.
Défis, risques & facteurs critiques de succès
Une dépendance majeure de la gestion des problèmes est l'établissement d'un processus et d'outils de gestion des incidents efficaces. Cela permet d'assurer que les problèmes soient identifiés le plus tôt possible. Il est essentiel que les deux processus aient des interfaces formelles et des pratiques de travail communes. Ceci implique :
- Être capable de relier les incidents et les problèmes.
- Les différents niveaux de soutien devraient avoir une bonne relation de travail avec le soutien de première ligne.
- S'assurer que l'impact d'affaires est bien compris par le personnel impliqué dans la résolution de problèmes.
- Une base de données de gestion des configurations à jour et disponible.
Merci, votre message a bien été envoyé.