Table of contents
Related Articles
Problem Management - Octopus Module
Introduction
Problem Management is an ITIL® process that is part of the Service Operation phase:
Objectives
Problem Management is the process that is responsible for managing the lifecycle of all problems. The main objectives are: proactively prevent incidents from occurring and minimize the impact of those that can not be avoided.
Scope
Problem Management includes required activities to diagnose the root cause of incidents and to determine the resolution to those problems. It is also responsible for ensuring that the resolution is implemented through the appropriate control procedure, especially Change Management and Release and Deployment Management processes.
Problem Management will also maintain information about problems and the appropriate workarounds and resolution, so that the organization is able to reduce the number and impact of incidents over time.
Although incident and problem management are separated processes, they are closely related and will typically use the same tools, and may use similar categorization, impact and priority coding systems.
Value
Problem Management works with Incident Management and Change Management to assure an improvement on IT Services availability and quality. When incidents are resolved, the resolution information is saved. Over time, this information is used to speed up the resolution time and to identify permanent solutions, reducing the amount and the resolution time of incidents. This results in less downtime and less disruptions for the enterprise critical systems.
Also, we notice:
- Higher availability of IT Services
- Higher productivity of IT staff
- Reduced expenditure on workarounds or fixes that do not work
- Reduction in cost of effort in fire-fighting or resolving repeat incidents
Definitions
Please consult Problem Management section on the ITIL® Glossary.
Activities
Problem Management are based on two concepts:
- Reactive Problem Management activities - typically triggered in reaction to an incident that has taken place
- Proactive Problem Management activities - triggered by activities seeking to improve services, and is generally conducted by Continual Service Improvement
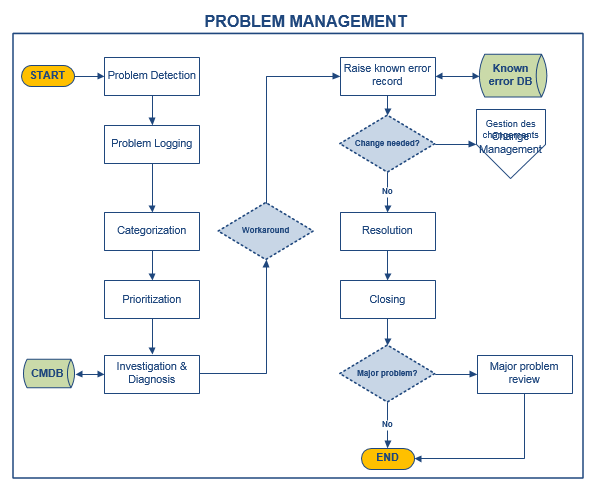
Detection : According to the organization, problem detection can vary. It includes :
- Suspicion or detection of a cause of one or more incidents by the Service Desk. The incident may have been resolved, but a definitive cause has not been identified and the incident may occur again. Or it could be evident from start that one or more incidents are caused by a major problem. In this case, a problem record will be raised without delay
- Analysis of an incident by a technical support group which reveals that an underlying problem exists, or is likely to exist
- Automated detection of an infrastructure or application fault, using event/alert tools automatically to raise an incident which may reveal the need for a problem record
-
A notification from a supplier or that a problem exists that has to be resolved
-
Analysis of historical incident records to identify an underlying cause, a workaround and/or a permanent solution
Regular analysis of incident and problem data must be performed to identify any trends as they become discernible
Logging: Regardless of the detection method, relevant details of the problem must be recorded. A relationship between incident(s) and a problem must be established. Information from the incident needs to be transferred in the problem, such as:
- User details
- Service details
- Equipment details
- Date/time initially logged
- Priority and categorization details
- Incident description
- Details of all diagnostic or attempted recovery action taken
Categorization: Problems must be categorized in the same way as incidents so that meaningful information can be easily obtained.
Priority: Problems should be prioritized the same way using the same reasons as incidents. The frequency and impact of related incidents must also be taken into account. The priority matrix, which combines incident impact with urgency to give an overall priority level can be used, on the condition that definition and guidance on what constitutes a problem are defined and communicated to groups that are implicated into Problem Management.
Problem prioritization should also take into account the severity of the problems, which may refers in this context to how serious the problem is in an infrastructure perspective (or service or customer perspective). Examples:
- Can the system be recovered, or does it need to be replaced?
- How much will it cost?
- How many people, with what skills, will be needed to fix the problem?
- How long will it take to fix the problem?
- How extensive is the problem (e.g.. how many CIs are affected?)?
Investigation & Diagnosis: An investigation should be conducted to try to diagnose the root cause of the problem. The speed and nature of this investigation will vary depending upon the impact, severity and urgency of the problem, but the appropriate level of resources and expertise should be applied to find a resolution according to the priority code allocated and the service target in place for that priority level.
The Configuration Management System (CMS) is used to help determine the level of impact, pinpoint and diagnose the exact point of failure. Also, it is possible to investigate if the problem occurred before and in which context in order to search for a solution.
It is often valuable to try to recreate the failure to understand what has gone wrong, and then try various ways of finding the most appropriate and cost-effective resolution to the problem. To proceed effectively without causing further disruption to users, a "test" environment can be used to recreate the problem can be useful.
Several problem analysis, diagnosis and resolution techniques exist. The more popular are:
- Chronological Analysis: all available data concerning the problems are gathered and filtered by date and period to provide a detailed chronological timeline.
- Pain Value Analysis: helps to identify the impact on business based by one or more problems. A formula is used to calculate the pain value; it is based on the number of affected users, the non-availability duration, the impact on each user and the cost for the business (if known).
- Kepner & Tregoe Method: the problem is analyzed in terms of "what, where, when and scope". Causes are identified. The most probable cause is tested. The actual cause is verified.
- Brainstorming: group or individual creativity technique by which efforts are made to find a conclusion for a problem by gathering a list of ideas spontaneously contributed by its member(s).
- Ishikawa Diagram: technique that helps a team to identify all the possible causes of a problem. Created by Kaoru Ishikawa, the result of this technique is a diagram looking like a fish bone.
- Pareto Analysis or Pareto Chart: technique to prioritize activities. Pareto Analysis says that 80% of an activity value is created by 20% of effort. Pareto Analysis is used in Problem Management to define the investigation priority of the possible causes of a problem.
Workaround: it is up to Problem Management to find a workaround to incidents having an unknown cause, to restore the service as soon as possible. Problem Management can require time to find a cause and identify a permanent solution, which could involve Change Management and Release and Deployment Management. The workaround will provide the Service Desk with a temporary solution to resolve recurrent incidents until a final solution is implemented.
Recording of a known error: once the diagnosis is completed and a temporary or permanent solution is identified, the problem becomes a known error. Thus, if other incidents or problems occur, they can be identified and the service restored more quickly.
Resolution: to resolve a problem, a permanent solution must be applied to eliminate the source causing incidents. The solutions often affect production environment, whether an infrastructure component or an application. In this case, in order to avoid further difficulties, the solution will be presented to Change Management, and scheduled and approved before being applied in production. In the case of an urgent problem that seriously affects the business, the urgent change process will be invoked.
Sometimes a solution to a problem may be delayed or may never be implemented - for budget reasons, because the impact is limited compared to the high costs or simply because it has not been prioritized. In this case, the problem remains open and we apply the workaround.
Closure: when a change is successfully completed and the resolution is applied, the problem should be formally closed, along with related incidents still opened. Problem documentation must be updated to make sure that the resolved problem contains all pertinent information for future references.
Major Problem Review: after a major problem occurred, a review is made to identify lessons learned for future references. The group should examine:
- What has been done correctly
- What has not been done correctly
- What should be done in the future
- How to prevent recurrence
- If there was any responsibility of third parties and if follow-up action is necessary
These revisions can be used in training and education of support staff. They offer opportunities for documentation of procedures, work instructions, or other, which will be used for the benefit of a better Problem Management.
Challenges, risks and success critical factors
A major dependency in Problem Management is to establish an effective process and tools in Incident Management. This ensures that problems are identified as early as possible. It is essential that the two processes have formal interfaces and common work practices. This implies:
- Being able to link incidents and problems
- The different levels of support should have a good working relationship with the first line support
- Ensure that the business impact is well understood by staff involved in problem resolution
- A configuration management database (CMDB) up-to-date and available
Thank you, your message has been sent.